
Overdetermined speech and music mixtures for human‐robot interaction
It is important for human shaped robots that interact with humans, to be capable of reacting to speech commands. Before being able to understand the human (speech recognition), the sounds recorded from the scene need to be separated correctly. Think of, for example, a robot that serves drinks at a cocktail party and humans telling the robot what kind of drink they would like. Instinctively, when people talk to human shaped robots, they talk to the head of the robot. It is well known that the recording process on the head of the robot is significantly affected by the shape and characteristics of the head. This task is to investigate how well source separation algorithms perform in this special scenario and also what configuration of microphones allows good separation results.
Results
Please see the result webpageTest data
Download humanrobot.zip
These files are licensed for research use only by their authors (see list of authors below).
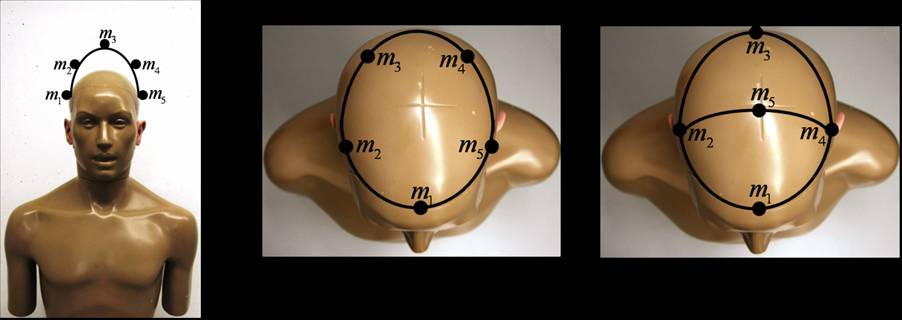
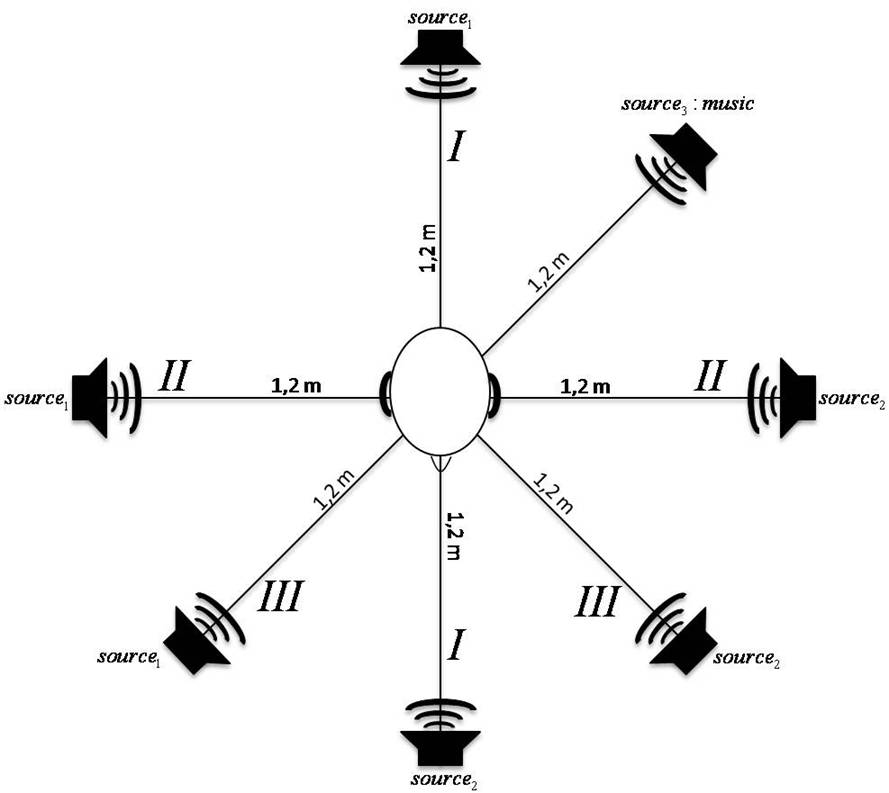
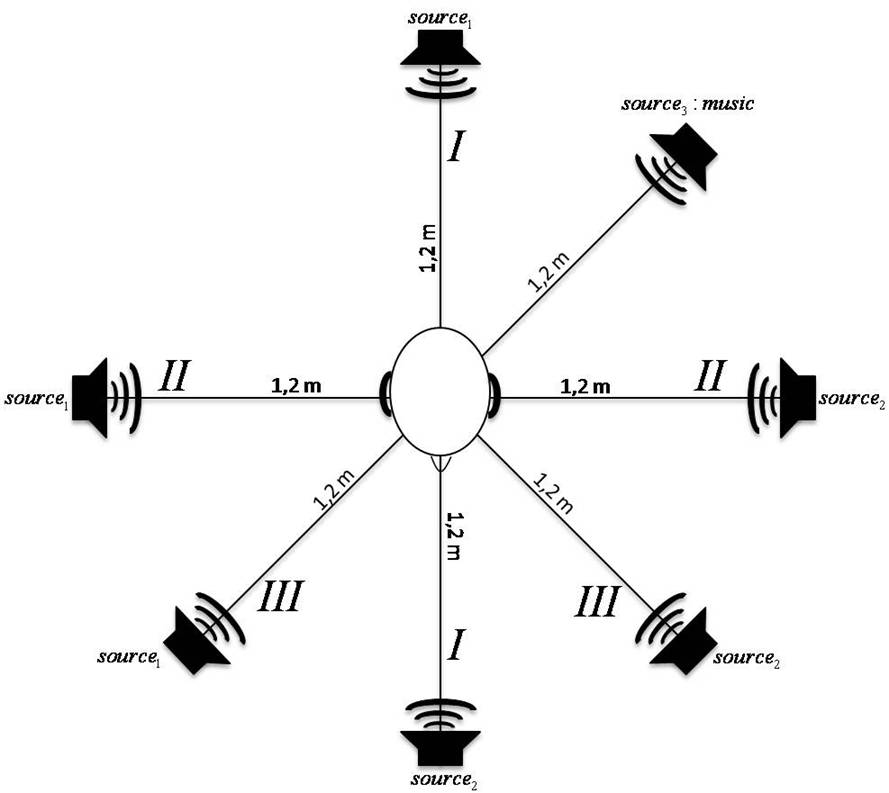
Sounds are recorded with five microphones attached to the head of a dummy. We investigate three different configurations of the microphones (see Fig.1), in three scenarios:
{kind=link}
- audiolab (4.7m × 3.7m × 2.9m)
- fully installed office (5.2m × 3.5m × 3.1m)
- cafeteria of the faculty for EI at the Technische Universität München
Three mono sound source
- 1 female speech source
- 1 male speech source
- 1 music source
{kind=link}
The filenames are build as <Room>-H<mic_setup_number>C<speaker_setup_number>.wav. For example Office-H2C3?.wav denotes the recording created in the Office with mic setup 2 and speaker setup 3. The mic and speaker setups can be seen in the images in the downloadable zip-file.
Each file is a standard wav-File with five channels of audio, one channel per mic.
- Sample rate: 16000 Hz
- Format: 16 bit signed integer
- Channels: 5
Task
The task is to recover the two speech signals from the 5 recorded audio files. The music extraction is NOT included in this task.
- Source signal estimation (estimate the mono source signals)
Submission method
[SUBMISSION CLOSED on Apr.21]
Each participant is asked to submit the results of his/her algorithm.
Each participant should make his results available online in the form of a tarball called <YourName>_humanrobot.zip.
The included files must be named
- <Room>-H<mic_setup_number>C<speaker_setup_number>_src_<j>.wav: estimated source <j>, mono WAV file sampled at 16 kHz
[SUBMISSION CLOSED on Apr.21]
Each participant should then send an email to "kleinsteuber (a) tum.de" with Cc to "shoko (a) cslab.kecl.ntt.co.jp" providing:
- contact information (name, affiliation)
- basic information about his/her algorithm, including its average running time (in seconds per test excerpt and per GHz of CPU) and a bibliographical reference if possible
- the URL of the tarball(s)
Evaluation Criteria
We plan to use the criteria defined in the BSS_EVAL
We have to note that, as the groundtruth, we have original source signals, but we don't have source image signals. Therefore, the submitted results will be evaluated with SIR, SAR, ISR, using original sources as "s" in bss_eval_sources.m.
Reference software:
* bss_eval_sources.m
Task proposed by M. Durkovic, M. Kleinsteuber, M. Rothbucher, and H. Shen
Back to Audio source separation top
{kind=link}
{kind=link}